

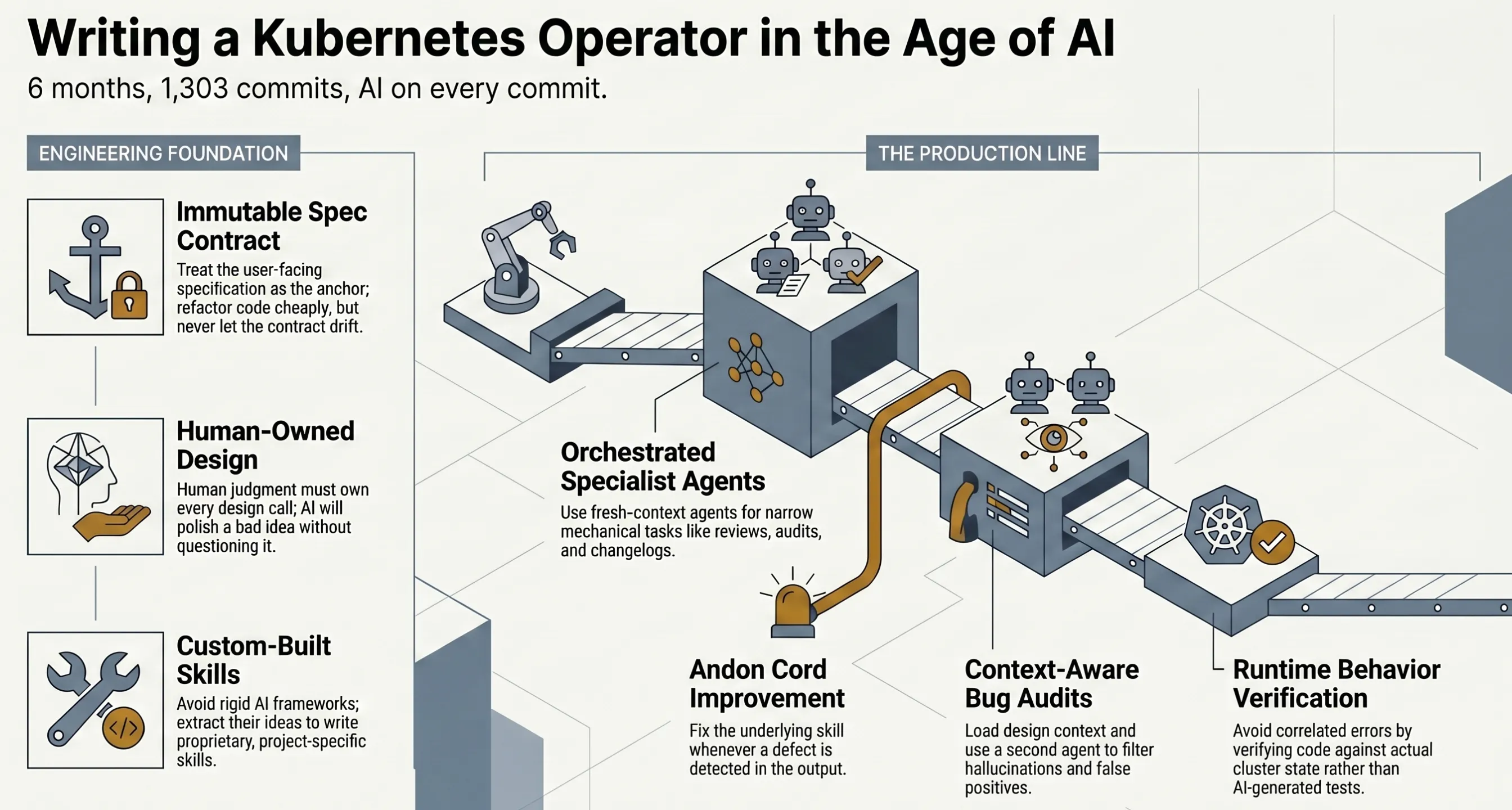
TL;DR
- Treat the user-facing spec as the one thing that can’t drift. Everything else is cheap to refactor; the contract isn’t.
- Don’t install AI frameworks. Read them, steal the ideas, and write your own skills instead.
- Run the mechanical work — reviews, audits, commit messages, changelogs, doc checks — as a factory of fresh-context agents, each with one narrow job, orchestrated by processes you control. Share them with the team so the development is consistent
- When a skill lets something through, fix the skill. Bad outputs are defects in the line, not one-off noise.
- Bug audits need design context loaded up front and a second agent to filter hallucinations, or you drown in false positives.
- Tests and code from the same AI source share the same blind spots. Verify against real runtime behavior instead of obsessing over 100% code coverage — this is especially true on greenfield projects.
- AI won’t tell you a bad idea is a bad idea. It’ll just build a polished version of it. Human judgment still owns every design call.
Six months into building a production Kubernetes operator for Multigres with AI, the code stopped being the hard part. Most of the effort went into design, hygiene, continuous improvement, and review. What I learned in 1,303 commits is that the best way to use AI is to build a factory floor of specialists you orchestrate yourself.
Understanding the domain
We were contracted to work closely with the Multigres team, led by Sugu Sougoumarane, the creator of Vitess, building a new distributed Postgres system. The operator’s job was to act as a provisioner of Multigres on Kubernetes, enabling users to use it simply and declaratively.
For a reader who hasn’t built a Kubernetes operator before, “an operator for a distributed database” is much more involved than it sounds. The operator provisions cells, shards, and connection pools, registers each piece with a topology service, and keeps the running cluster converging toward whatever the user put in a YAML.
The hard part is the state transitions. Scaling down can’t just delete a pod. If that pod is the primary Postgres, deleting it loses data. The operator has to coordinate with the replication state machine, demote the primary, wait for standbys to catch up, and unregister from the topology before Kubernetes can safely garbage-collect. Scale-up has its own dance that StatefulSets couldn’t carry, so we built our own pod management.
All of this happens through Kubernetes’ declarative model, where any piece can fail at any time and the operator’s job is to keep nudging the world toward the desired shape.
Three things made the job harder than an average operator build:
- Multigres was still in very early stages of development, which made it a moving target for us to design and implement the operator against.
- It required relatively complex templating logic across multiple CRDs and component types.
- Multigres, like Vitess, is middleware over an unsharded engine, which pushes a lot of database-layer orchestration into the operator itself rather than into the database.
On that last point: where does placement and rebalancing actually live?
In databases like CockroachDB, TiDB, and YugabyteDB, the answer is inside the database. Add a node and it automatically starts taking on data. Decommission one and the cluster moves the data off before you can safely remove it. The operator’s job on scale events is mostly to signal intent and wait.
Vitess and Multigres work differently, by design. They keep the engine (MySQL or Postgres) unmodified — stock, unsharded, with no concept of cluster membership. You get SQL compatibility, mature tooling, and shard isolation out of the box, which is the whole point. The trade-off is that resharding and decommissioning can’t live inside the database, so they have to be orchestrated externally. That pushes responsibility and complexity into the operator and forces a richer YAML spec — the price of a heavier control plane for a well-understood storage layer.
In practice this meant our operator had to drive Postgres-layer orchestration directly: checking whether a pod was a primary, coordinating demotion, waiting for synchronous standbys to catch up, unregistering from the topology service, and only then letting Kubernetes delete the pod.
Understanding the domain took a chunk of our time, and it was well spent. It involved reviewing the Multigres codebase and design documents as well as reviewing all the operator and controller-runtime features to see what we would need and how we would design the work.
Having AI as a companion at this stage was also very helpful because we could feed it the entire codebase and documentation and ask questions, no matter how dumb, about everything. It really made the research period much quicker and easier and it took a big load off the Multigres team having to bring us up to speed.
The spec was the decision that paid for itself
Before we started implementation we wrote a spec as part of the design process. Spec-driven development gets dismissed as waterfall theater and I understand why. Historically the argument against it was that by the time you finish the spec, the world has moved and the spec is wrong. That’s still partly true.
What’s also true is that AI changes the math. If a small team plus a coding agent can produce three incompatible designs for the same feature in a week, the thing you cannot let drift is the user-facing contract.
Everything else can churn without much cost, because refactoring is now cheap. But the surface the user interacts with has to be stable, because it’s the single anchor that keeps agents, humans, and the client all aimed at the same target.
So we wrote the spec the way a user would read it. CR YAMLs with every alternative option inline as a comment, plain-English descriptions of what each field does sitting right next to the field, and the operator’s drain and upgrade semantics written out in prose rather than locked in a state diagram. It looked more like a product doc than a design doc, which is the point.
The spec took weeks because it involved a lot of redrafting and discussions with the Multigres team. That felt long, but looking back I think they were the most important weeks of the project. Every hour spent iterating on the spec with the Multigres team saved days of implementation we would have later thrown away.
Once we were happy with the result, the spec was used as a base to generate the different parts of the code with AI.
Defining the how
The spec tells the user what the operator does. It doesn’t tell the team how to implement it. That’s a separate exercise, and it has to happen early, because AI will happily write code in whatever style it inferred from training data — not the style your codebase actually wants.
There are roughly four things to nail down:
- How the code is structured: packages, layering, naming.
- Which best practices you’re following (for us, Google’s Go Style Guide).
- Hard rules: what you will do, what you will not do, where exceptions are allowed. AI sometimes ignores these, which is why additional agents and you double-checking the work are sometimes essential.
- Testing conventions: what gets covered, how deep, which tools.
None of this is only for AI. Humans reading each other’s code need the same shared vocabulary. In a team that’s part humans and part agents, the conventions become the shared grammar that lets both groups work on the same codebase without talking past each other.
The trick is to not stuff all of this into a 3,000-line CLAUDE.md that loads into every context window. The Go style guide alone would eat half your context on every turn.
A better pattern is to make each convention its own skill that the implementation agent doesn’t read by default. After a change is written, a fresh-context agent runs the relevant skill (Go style, design-doc compliance, test-coverage rules) and audits the diff against that specific convention. The implementation agent stays lean, and the reviewer only sees the diff and the rule it’s checking.
When you want to update a convention, you edit the skill. The review agent picks up the change the next time it runs.
AI tooling
I went through several tools to land where I landed. Writing down the whole arc in case it helps someone skip the dead ends.
I started with Gemini Pro in a plain chat window, pasting in code folders and asking questions. It works well for research and for understanding a new codebase. It doesn’t work well for sustained implementation because you’re the one operating the tools, there’s no agent, and the loop of “paste, wait, paste again” is slow and full of friction.
Then I moved to Google’s Antigravity, which bundles Gemini Pro and Claude in an IDE-like agent based on VSCode. When it worked, it was great. Their quota on the Ultra subscription was generous enough that running out of credits was basically impossible. But the backend was exceedingly unreliable in a way that made serious work frustrating. Jobs would cancel partway through all the time and you had to keep retrying by hand. Support was slow and didn’t take much ownership of the issues. I burned a lot of time retrying things that shouldn’t have needed retrying. Eventually I moved on.
Claude Code turned out to be the right tool for me for sustained engineering work. I pay for the $100 Ultra subscription. Early on I was running out of credits because the agent was consuming a lot of context on queries that involved reviewing two codebases and writing a lot of tests. Installing Context Mode, a community plugin that offloads large tool output into a sandbox, stopped that. I kept the cheaper subscription instead of upgrading. The Context Mode plugin is more important than ever now that all AI subscription providers are beginning to dramatically lower quotas.
The other important realization about tooling was that the AI coding ecosystem grew an enormous amount of tooling in a short time: SpecKit, Superpowers, Agent-skills, a new 500-star repo every other week. The ideas inside them are usually great. Installing a framework pushes you into its worldview. You inherit its rigidity, its token overhead, and the opinions of someone who wasn’t building the exact thing you’re building.
For example, I’m a huge believer in Spec Driven Development, but SpecKit didn’t land for me. Every command it adds has a simpler, native alternative you probably already have: CLAUDE.md, plain markdown design docs, GitHub issues, skills, native TodoWrite. Installing it means trading the agency to build your own tighter, project-specific version for someone else’s rulebook.
Then you have bundles of skills (Claude Plugins) like Superpowers and Agent-skills. Superpowers forces worktrees, TDD, and brainstorming on you whether or not those fit the work you’re actually doing. Agent-skills dumps dozens of skills into your config that you’ll never audit. Both have good ideas you should steal but don’t install either as-is. Read them, then write your own skills. With AI in the loop, writing a skill is cheap enough that there’s no excuse not to.
The only third-party tools I’d install now are ones scoped to a single job. Skill Creator helps you author and refine skills without trying to run your workflow. Context Mode keeps context usage in check. Both small, both scoped. Neither is trying to run my workflow for me.
Implementation
Early on the dev loop looked like pair programming with a lightning-fast partner: read the spec, prompt the agent, review the diff, fix what was wrong, ask for the tests, iterate. I reviewed other people’s branches the same way, pulling them down and walking the diff with a fresh conversation. That worked while I was still learning what the operator wanted to be.
Later we dropped PR reviews entirely because they were too slow for a greenfield project under a tight deadline. Designs got reviewed up front; execution got corrected as it went, through bug audits and refactoring. I probably wouldn’t do this on a system already in production, but for greenfield under deadline it was the right call — especially given how fast you can refactor or change course with AI in the loop.
The code stopped being the hard part. The time sink was all the hygiene work around every change. Writing commit messages. Chasing regenerated CRDs. Re-reading design docs to make sure a change hadn’t quietly contradicted something we’d decided in week two. The Go style guide — which parts applied to the file I’d just touched? The mechanical stuff a senior engineer does in their head during review, except there was a lot more of it now, because a lot more code was moving, which is when I started building the factory.
The factory: running engineering like a production line
Note: Much of what’s said here overlaps a lot with Harness Engineering. There are a couple of reasons why I am changing the terminology a bit here. When I was working with Claude Code, Antigravity and others Harness Engineering wasn’t a big thing, it only surfaced towards the end of our project. Now that I am reading about it, I can see it aligns with a lot of what I was doing already (described below). Another reason is that I found out about Harness Engineering after I wrote the first draft of this article, and I like my factory terminology better to describe this way of working.
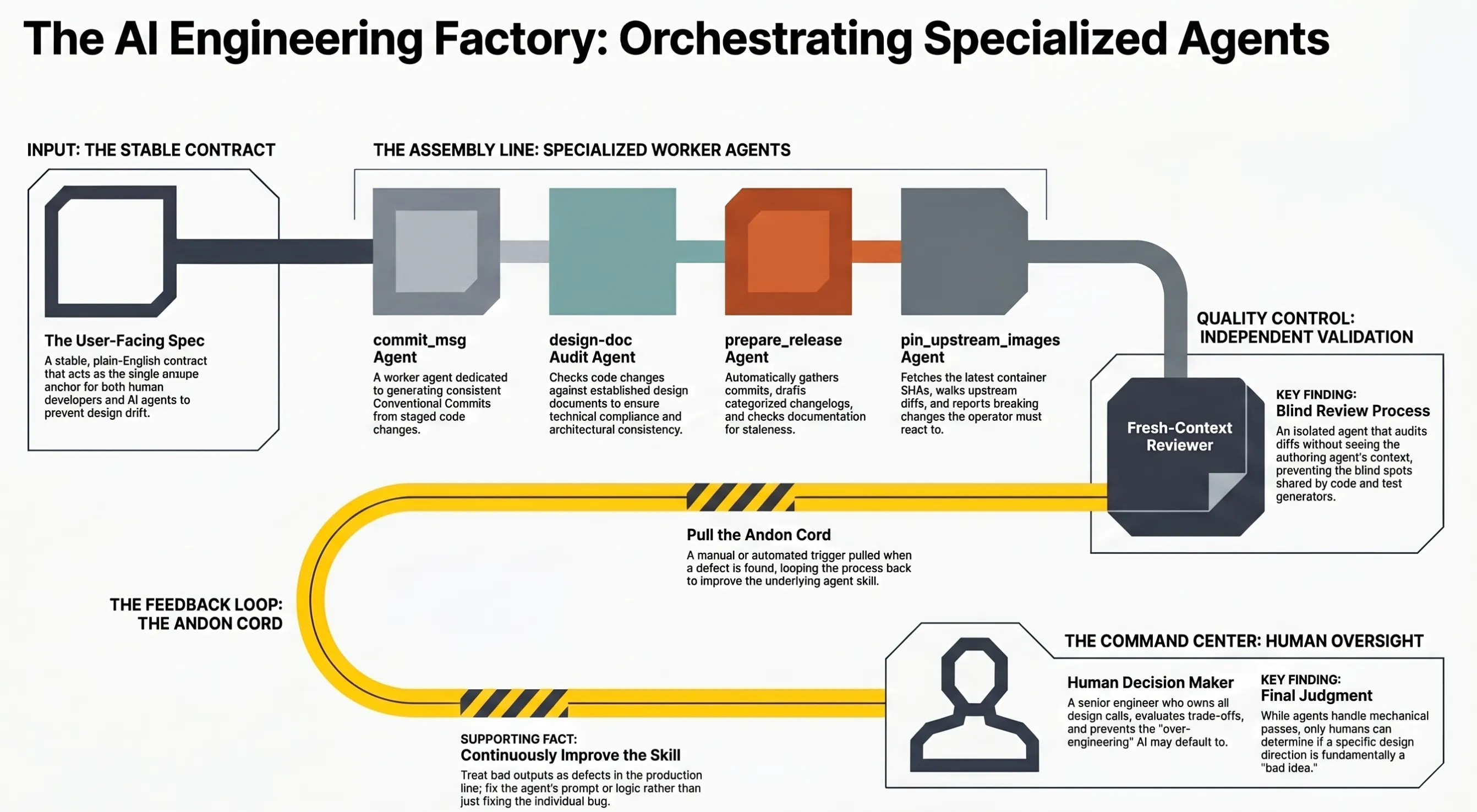
If a factory has different processes and worker specialists, so should your project. Think of a “factory worker” as a fresh-context agent with one narrow job, a skill it reads before starting and your factory floor is whatever harness you use (i.e. Claude Code, Antigravity, Codex, etc). If the worker is a reviewer, it should have no attachment to the code it’s looking at.
That last part matters. The agent that wrote the code is invested in it being correct, exactly the way a human author is invested in their own draft. A fresh agent has no stake. If you want independent review you need independent context.
Your processes can also be skills that call other skills, and you can trigger these manually or by using whatever hooks are available to you. That way it does not pollute your context with a big CLAUDE.md. Say you want a process to code, review, verify and push. You can have a skill that calls a skill for each one of those. The important thing is that you understand and create your own factory floor and assign the jobs yourself. This is one area I would have invested a lot more time on if I had stayed longer on the project.
In the short time I was allocated for this project I built skills for the mechanical passes: Go style, integration test triage, kind cluster lifecycle, CRD regeneration, design doc compliance checks, documentation audits. Most stay local to me because they encode individual workflow preferences. The three we checked into the repo for the whole team to use live under tools/skills/, because they’re release-adjacent and the team benefits from running them the same way:
generate_commit_message: produces a Conventional Commit from staged changes.pin_upstream_images: bumps multigres container image tags and walks the upstream diff between old and new SHAs to flag anything the operator needs to react to.prepare_release: gathers commits since the last tag, classifies them, drafts a categorized changelog entry, infers the next semver bump, and audits every file underdocs/for staleness.
pin_upstream_images shows what the factory model is good for. When Multigres ships a new build, we need to point the operator at the new image SHAs. By hand that means fetching the latest sha-* tags, resolving which digests they map to, reading the upstream diff between the old and new SHAs to figure out whether anything the operator relies on has changed, deciding whether we need to react, and then updating the constants in api/v1alpha1/image_defaults.go. All of it is mechanical except the middle step, which requires reading a diff and thinking.
The skill automates the mechanical parts and structures the thinking. It runs the tag-fetch script, updates the constants, walks the upstream diff section by section, and produces a report of breaking changes, new features, and anything the operator should care about. A fresh-context agent runs this against every release candidate. The output is a consistent, structured summary of what moved upstream, which is exactly the artifact you want before bumping a production dependency.
prepare_release does something similar for changelogs, plus it audits every file under docs/ for staleness introduced by the changes it just summarized. That keeps the codebase and the docs from drifting out of sync. A fresh agent will grind through sixty doc files in ten minutes and flag every stale sentence, which is not something I was going to do by hand on every release.
The Andon Cord
The rule I hold the factory to is that when a skill produces a bad or even mediocre output, you don’t shrug it off. You pull that andon cord and fix the skill. Every time a gate lets through a real bug, a wrong commit message, or a stale doc, the corresponding skill gets updated. After a few months of doing this the factory gets sharp and stays that way, because every miss turns into a permanent fix.
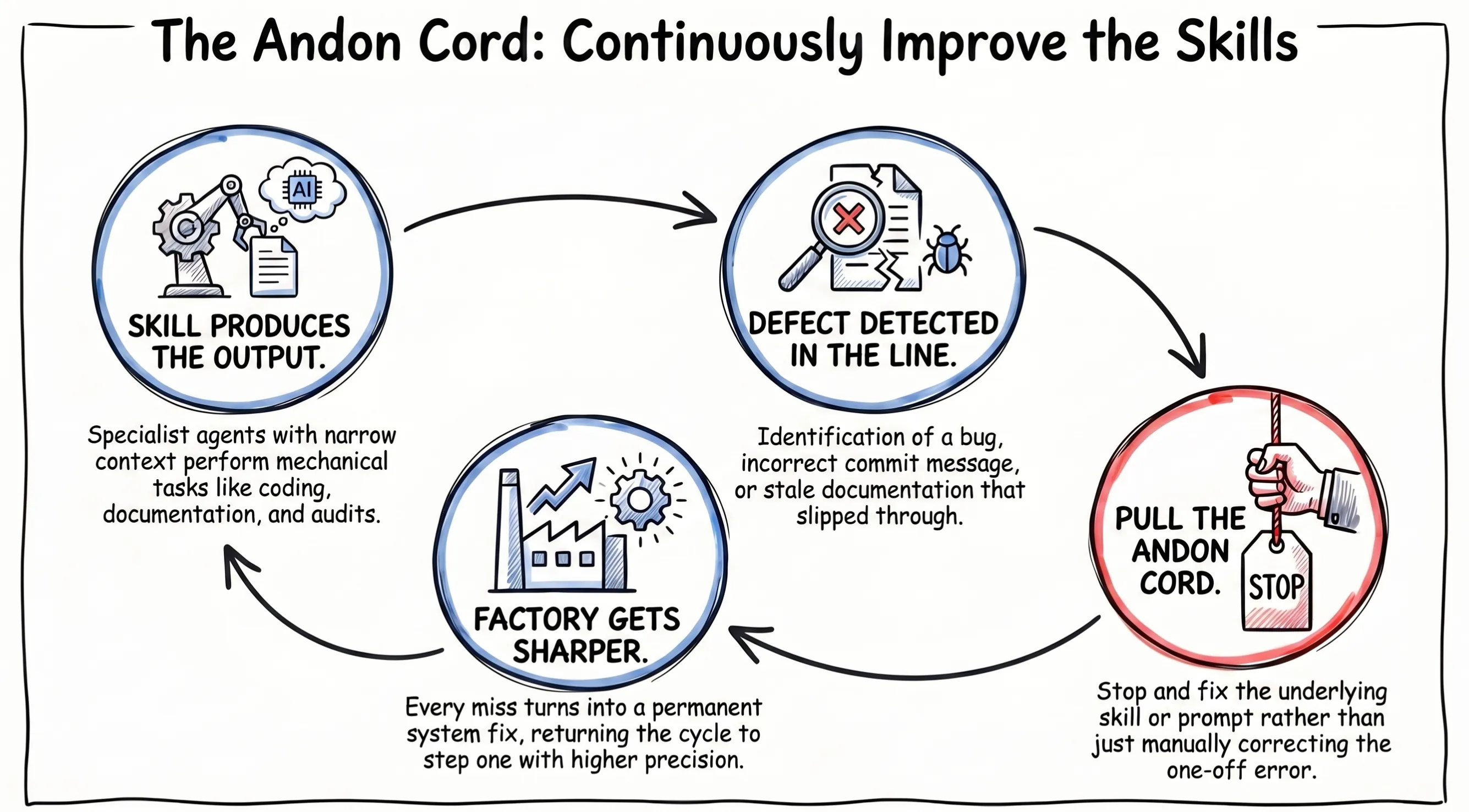
For example, the observer skill was improved and modified after almost every run. SKILL.md grew to 557 lines, with a sibling scenarios.md at 1,245 lines. Every invocation loaded all of it into context, even for runs that only needed a small slice. Commit f89a4bc restructured it for progressive disclosure: SKILL.md down to 194 lines, scenarios split across eight on-demand files, 83% less token load on the core path. Pulling the cord means fixing things like this before they rot the rest of the line.
There’s a popular idea in AI-coding circles called the “Ralph Wiggum loop”, coined by Geoffrey Huntley, which is the practice of handing an agent a spec, putting it on a loop, and coming back in a week. It works for bounded mechanical tasks.
This and other agent self-improvement methods like Karpathy’s Autoresearch are ideal for scenarios where you have a very clear idea of what the targets are. In a complex, continuously changing system where those targets aren’t as easily defined or the design is still taking shape, it doesn’t work so well, because big projects need decisions made during development. A controller design surfaces a tradeoff you didn’t see coming, or an upstream change forces a rethink, or a test reveals your assumption was wrong. A loop with no supervision will make those decisions silently and badly, and by the time you look at the output it’s too tangled to cheaply fix.
The factory is the opposite shape. I make the decisions; agents handle the mechanical passes. Every pass is a fresh context, so fatigue doesn’t accumulate across reviews.
Bug audits
Something else I did with AI was run bug audits regularly. Over the course of the project they surfaced a lot of real bugs: commit bc1c924 resolved seven, 75d0ab1 fixed eight more, da7d639 cleaned up another batch. Each audit round caught things the test suite and manual review had missed.
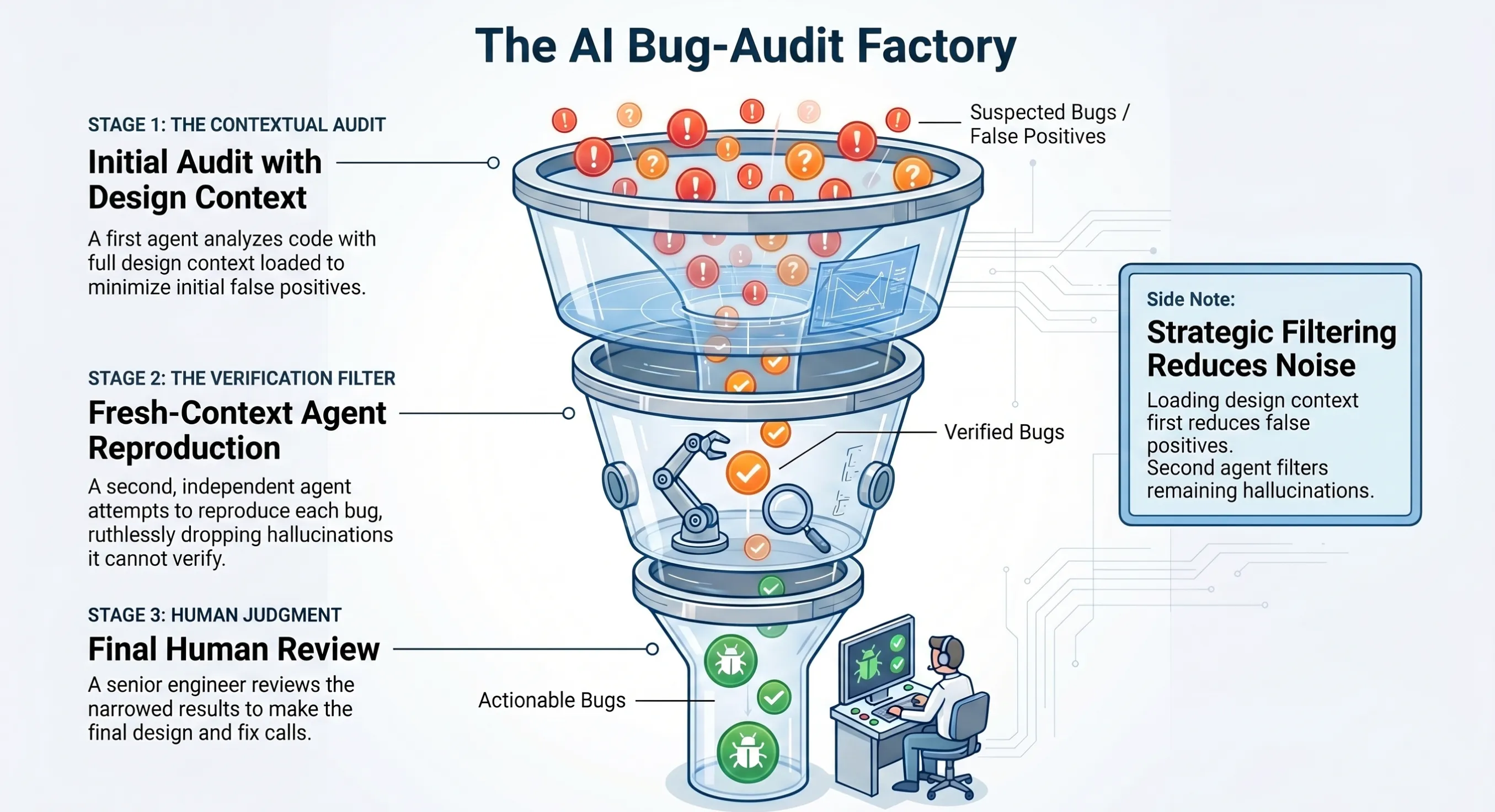
AI is genuinely good at this. A fresh-context agent with the right prompt and scope can comb through thousands of lines of Go and flag suspicious patterns a human would either miss or take days to find.
But bug audits also hallucinate a lot. Without the right context, the agent confidently flags code as broken when it’s actually working as designed. “This function doesn’t handle the nil case” (ignoring that the caller always passes a non-nil value by contract). “This controller doesn’t handle deletion” (ignoring that deletion is handled through ownerReferences rather than explicit code).
The pattern is missing-the-forest-for-the-trees. The AI reads each file’s local logic without the surrounding invariants, and flags behavior that looks wrong in isolation but is correct in context.
The way to get them to stick was to feed the agent the design docs first, have a conversation about how the controllers coordinate and what the ownership model is, and only then ask for the audit. Running it cold produced a mountain of false positives. With the design loaded in, the agent has some sense of why the code is shaped the way it is. I also stopped asking “audit the operator for bugs” and started asking “audit the shard controller’s drain state machine for bugs, given this design doc.” The second prompt produced sharper findings.
The bigger thing was running a second fresh-context agent over the first agent’s report. The second agent’s job was to verify if the bugs were legitimate and/or reproduce each bug and drop anything it couldn’t. That’s where most of the hallucinations got filtered before I reviewed it myself.
Between bug audits and the observer we had a way to catch problems that lived in the code and problems that only showed up with a running cluster. Treat audits as a required pass in the loop. They almost always surfaced something, sometimes trivial, sometimes load-bearing, and on a greenfield project moving this fast they were essential.
AI Human failure
One bug we had in the project was a pod-matching issue in the drain state machine. The code matched Kubernetes pods to topology records by stringifying a protobuf message with fmt.Sprintf("%v", p.Id). On a protobuf that produces the text-format representation, not the name field. So instead of comparing "pool-shard-0-0" to "pool-shard-0-0", the code was comparing "name:\"pool-shard-0-0\"" to "pool-shard-0-0". It never matched, so drain never worked.
The same agent that wrote the code also wrote the tests, and those tests stringified the protobuf the same way to generate expected values. The tests kept passing for weeks while drain was quietly broken.
AI writes syntactically fine code that does the wrong thing. When the same source writes the code and the tests, they share the same misunderstanding, so the tests pass and the feature is still broken. I wrote up the broader lesson in a separate post, Testing Operators in the Age of AI. The short version is that unit tests from the same source share the code’s blind spots, so the verification has to come from somewhere else. In our stack that was the observer, checking real cluster state against invariants that the operator’s own code couldn’t see.
Other issues we had were with poor initial judgment. We originally decided on finalizer state machines across the MultigresCluster, Shard, and TopoServer controllers to coordinate deletion lifecycle. Resources kept getting stuck in the deleting state, the controllers ended up fighting Kubernetes’ own garbage collection, and the tests were asserting complex state transitions that ultimately didn’t need to exist.
Separately, we’d split the shard data-handler out as its own controller for topo registration, drain coordination, and backup health, while the resource-handler owned the rest of the shard’s lifecycle. Cross-controller coordination produced race conditions during deletion and required SSA field exclusions so the two controllers didn’t clobber each other’s status fields.
Nothing about either of these surfaced itself. I had to notice the smell, decide the fix was worth doing, and put the work in.
That meant drafting a refactor proposal, reviewing it, discussing it with the Multigres team to make sure I wasn’t about to break an assumption on their side, and only then running it through implementation.
The refactor landed as a sequence of commits: 2d7e4a7 added the proposal, e5df27e merged the data-handler back into the resource-handler, and 9cb9471 ripped finalizers out and replaced them with best-effort cleanup relying on owner references. The end result was a smaller codebase, fewer edge cases, and a more reliable deletion path.
Those design calls were ours, not the AI’s. What AI didn’t do at any point was push back. It produced well-tested implementations of everything we asked for, including the finalizer state machines and the two-controller split, and never once said “have you considered that this is more than you need?” Human judgment has to come in at every stage because the AI won’t supply it. Without a senior engineer willing to say “this is more than we need, let’s cut it,” no amount of AI help is going to unwind the elaborate machinery you’re about to build.
Most of what looks like an “AI failure” is really a human one. We bring the wrong assumptions, or we expect the tool to read minds. Models will keep getting better at some of this, but until they do, you still have to catch what they miss.
What I would do differently
We spent too long on the spec’s edge cases in the first pass. The right bar is to be right about the shape and wrong about maybe 10% of the details. We overshot that, chased edge cases for extra weeks, and then still had to revise parts of the spec once real implementation exposed what we hadn’t anticipated. The lesson I took is that “good enough” is a harder discipline with AI than without, because writing more of the spec is also cheap, so the temptation to keep going is stronger.
When we initially started this project, our brain was still running a bit of the old pre-AI chip and we were doing things the classical way. I was slow to build the AI factory. The first skills we committed to tools/skills/ didn’t land until mid-March 2026, roughly five months into the project. Local per-engineer skills existed earlier, but the formal shift from hands-on-with-an-agent to fresh-context skills as a deliberate discipline happened much later than it should have. Every week in between was a week of hygiene work done by hand that could have been a skill. If I were starting a comparable project now I’d put two days of factory building into the first sprint, even before the first controller was done. That’s also slightly disingenuous for me to say, because the creation of these factory steps is much easier to define once you have walked the walk, but it’s a good exercise to start with at least the basics and the right mindset.
I underinvested in behavioral testing for too long. This is covered in the testing post in more detail, but the summary is that we chased coverage as a metric for months before I accepted that coverage wasn’t measuring what I thought it was. The observer was the right tool and I should have built it earlier.
I didn’t track costs well. I don’t have a clean number for how many dollars of AI subscriptions went into the operator, because nobody thought to track it until we were past the point where the answer would have been useful. That’s on me.
Further reading
Two specific slices of this work have their own write-ups with more detail than makes sense to repeat here.
Testing Operators in the Age of AI is the long version of the correlated-errors problem. It has the numbers: 65% of our Go code was test code, the most-modified file in the repo was a test file, and after hitting near-100% coverage we still found over twenty real bugs the suite had never caught. It argues for inverting the testing pyramid during active AI-assisted development, with behavioral tests and observers at the base and unit tests at the top, added once the architecture stabilizes.
Building Operators in the Age of AI is about kubebuilder specifically. We scaffolded with it on day one and then essentially stopped using it. What survived of the initial scaffold is the Makefile wiring, the config/ kustomize structure, and the initial go.mod. What didn’t survive was the flat internal/controller/ layout, the per-type webhook scaffolds, and the default main.go, all of which we replaced as the operator outgrew the shape kubebuilder assumed. The deep dive covers what kubebuilder still does well, what AI now does better, and what controller-runtime is and why it stays.
If you’re thinking about a similar project and want to talk through the tradeoffs, get in touch.